XIA LEI
XIA LEI 
Understanding Large Language Models: A Complete Guide
What is a Large Language Model?
Large Language Models (LLMs) are artificial intelligence models with massive parameter scales, trained on enormous amounts of data.
Core Characteristics:
- Massive Parameters: Typically ranging from billions to trillions of parameters, which determine the model's "knowledge" and capabilities.
- Trained on Vast Data: Pre-trained on large-scale corpora including internet text, books, code, and more.
- Strong General Capabilities: Not limited to a single task - they can write, translate, code, reason, answer questions, and perform many other tasks.
- Emergent Abilities: When model scale exceeds a certain threshold, capabilities appear that smaller models don't have (such as logical reasoning and generalization).
Notable Examples:
- GPT-4 (OpenAI)
- Claude (Anthropic)
- Gemini (Google)
- 文心一言 (Baidu)
- 通义千问 (Alibaba)
- DeepSeek
Underlying Technology:
Most large models are based on the Transformer architecture, developed through "pre-training + fine-tuning" methods, sometimes combined with Reinforcement Learning from Human Feedback (RLHF) to make model outputs better align with human expectations.
Simply put, a large language model is like a "super assistant who has read massive amounts of books," capable of understanding and generating language while completing various complex tasks.
The Mathematics Behind LLMs
Large models don't have a single "formula" - they're composed of many mathematical components. The core is the Transformer architecture, with the most critical formula being:
1. Self-Attention Mechanism
Attention(Q,K,V) = softmax(QK^T / √d_k) · V- Q (Query): What am I looking for?
- K (Key): What can I provide?
- V (Value): My actual content
- √d_k: Vector dimension, used for scaling to prevent gradient vanishing
This formula allows the model to learn which words in a sentence are most relevant to the current word.
2. Multi-Head Attention
MultiHead(Q,K,V) = Concat(head₁,...,headₕ) · W^OMultiple attention heads operate in parallel, understanding language from different perspectives.
3. Feed-Forward Network (FFN)
FFN(x) = max(0, xW₁ + b₁)W₂ + b₂Each Transformer layer contains a fully connected feed-forward network.
4. Training Objective (Language Modeling)
ℒ = -Σₜ log P(xₜ | x₁, x₂, ..., xₜ₋₁)This maximizes the probability of "predicting the next word based on previous words" - the core objective of LLM pre-training.
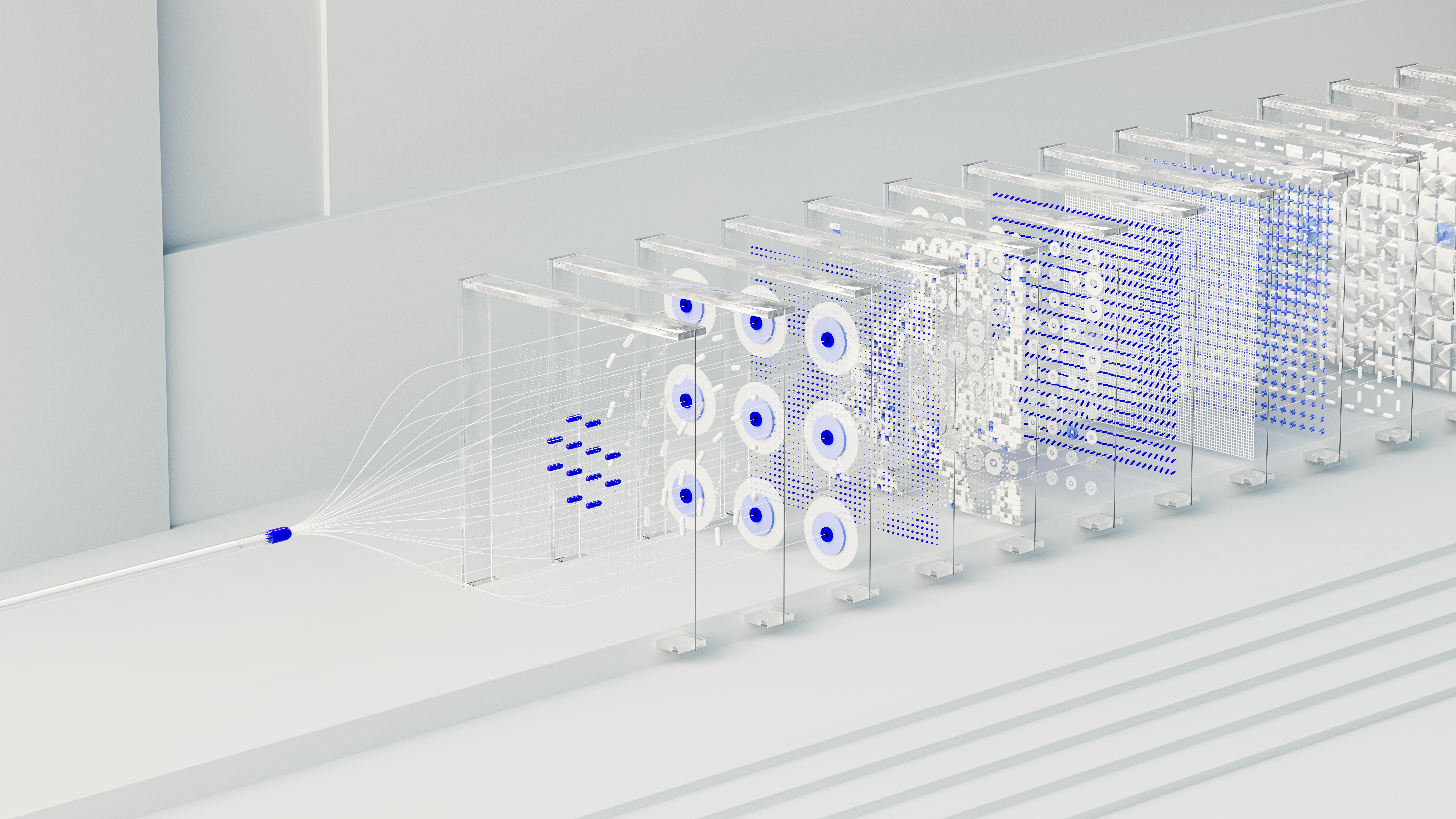
How It All Works Together
The overall process can be understood as:
Input text → Word embeddings → Multi-layer Transformer (attention + feed-forward) → Output probability distribution → Predict next word
Large language models are essentially extremely complex "next word predictors," but when the scale is large enough, they exhibit emergent high-level capabilities like understanding, reasoning, and creation.
Interactive Visualization
To better understand how Transformers work, explore our interactive 3D visualization that walks you through:
- Self-Attention mechanisms
- Multi-Head Attention
- Feed-Forward Networks
- Training objectives
Each step is visualized in 3D with detailed explanations of the mathematical operations happening under the hood.
Understanding Semantic Space: A Practical Example
Let's explore how AI actually processes and understands the meaning of words through a concrete example comparing two similar sentences: "I love you" and "I hate you".
How AI Represents Text as Numbers
When you input text into a language model, it doesn't understand words the way humans do. Instead, it converts each word into a vector - essentially a list of numbers (typically hundreds or thousands of dimensions).
Example:
- "I" → [0.23, -0.45, 0.67, 0.12, ...]
- "love" → [0.78, 0.34, -0.23, 0.91, ...]
- "you" → [-0.12, 0.56, 0.43, -0.34, ...]
Similarly:
- "I" → [0.23, -0.45, 0.67, 0.12, ...]
- "hate" → [-0.82, -0.67, 0.15, -0.73, ...]
- "you" → [-0.12, 0.56, 0.43, -0.34, ...]
Notice how "love" and "hate" have dramatically different number patterns, especially in key dimensions that capture emotional sentiment.
The Semantic Space
All these word vectors exist in what we call semantic space - a multi-dimensional mathematical space where:
- Words with similar meanings are positioned close together
- Words with opposite meanings are positioned far apart
- The distance and direction between words capture meaningful relationships
In this space:
- "love" and "adore" would be very close neighbors
- "hate" and "despise" would cluster together in a different region
- "love" and "hate" would be distant, potentially in opposite directions
How the AI Computes Understanding
When processing "I love you" vs "I hate you":
- Tokenization: Split into individual words/tokens
- Embedding: Convert each word to its vector representation
- Attention Calculation: The model computes how each word relates to others using the attention formula:
`` Attention Score = softmax(Query · Key / √d) ``
- Context Integration: Combine information from all words weighted by attention scores
- Semantic Understanding: The final representation captures that one sentence is positive, the other negative
The key insight: The model learned during training that vectors in the "love" region correlate with positive outcomes, while vectors in the "hate" region correlate with negative outcomes.
Explore It Yourself
See these concepts come to life in our interactive semantic space visualization, where you can:
- Visualize how words are positioned in 3D space
- See the distance between related and opposite concepts
- Understand how context shifts word meanings
- Explore the geometry of language understanding
This visualization demonstrates why "I love you" and "I hate you" - despite sharing two identical words - produce completely different AI responses: the critical word occupies entirely different regions of semantic space, leading to opposite interpretations.
Conclusion
Large Language Models represent a revolutionary breakthrough in artificial intelligence. By understanding their architecture - from attention mechanisms to training objectives - we can better appreciate both their capabilities and limitations.
The journey from simple neural networks to these sophisticated systems showcases the power of scale, architecture design, and the Transformer's elegant solution to processing sequential data.
Whether you're a developer, researcher, or simply curious about AI, understanding LLMs is essential for navigating our AI-powered future.